视觉SLAM学习笔记:五
矩阵求导
标量函数对向量求导

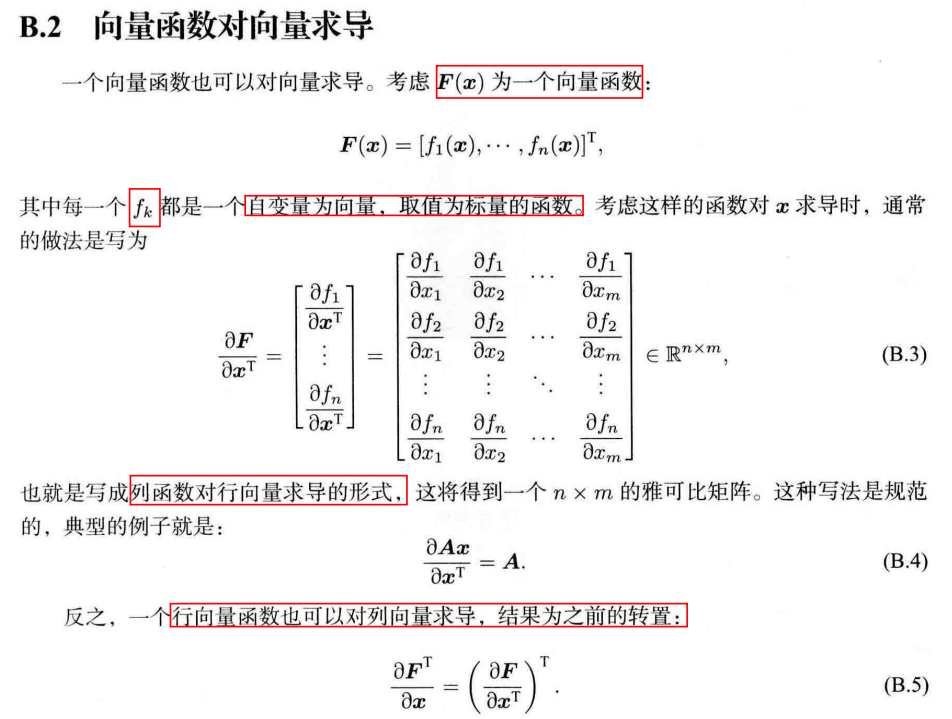
向量函数对向量求导
常用公式:
- 线性变换$$\frac{\partial Ax}{\partial x^{T}}=A$$
- 恒等变换$$\frac{\partial x}{\partial x^{T}}=I$$
- 零矩阵,a为常数向量$$\frac{\partial a}{\partial x^{T}}=0$$
- 梯度行向量($a^{T}x$是标量)$$\frac{\partial a^{T}x}{\partial x^{T}}=a^{T}$$
- 和$$\frac{\partial x^T a}{\partial x^{T}}=a^{T}$$
- 二次型梯度($x^{T}Ax$是标量)$$\frac{\partial x^{T} A x}{\partial x^{T}}=x^{T}(A+A^{T})$$
- 链式法则:若$z=f(y),y=g(x)$,则:$$\frac{\partial z}{\partial x^{T}}=\frac{\partial z}{\partial y^{T}}\cdot \frac{\partial y}{\partial x^{T}}$$
迹的性质
迹可以用于推导矩阵的导数
迹就是方阵主对角线元素之和,是一个标量
- 线性性$$tr(A+B)=tr(A)+tr(B)$$ $$tr(cA)=ctr(A),\;\;\;c\in \mathbb{R}$$
- 转置不变$$tr(A)=tr(A^{T})$$
- 循环置换(Cyclic Permutation)$$tr(ABC)=tr(BCA)=tr(CAB) \;\;\;\;\;\;\;\;\;tr(AB)=tr(BA)$$
- 标量即迹$$a=tr(a)$$
- 导数性质$$dtr(A)=tr(dA)$$
使用迹推导$x^{T}Ax$的求导公式: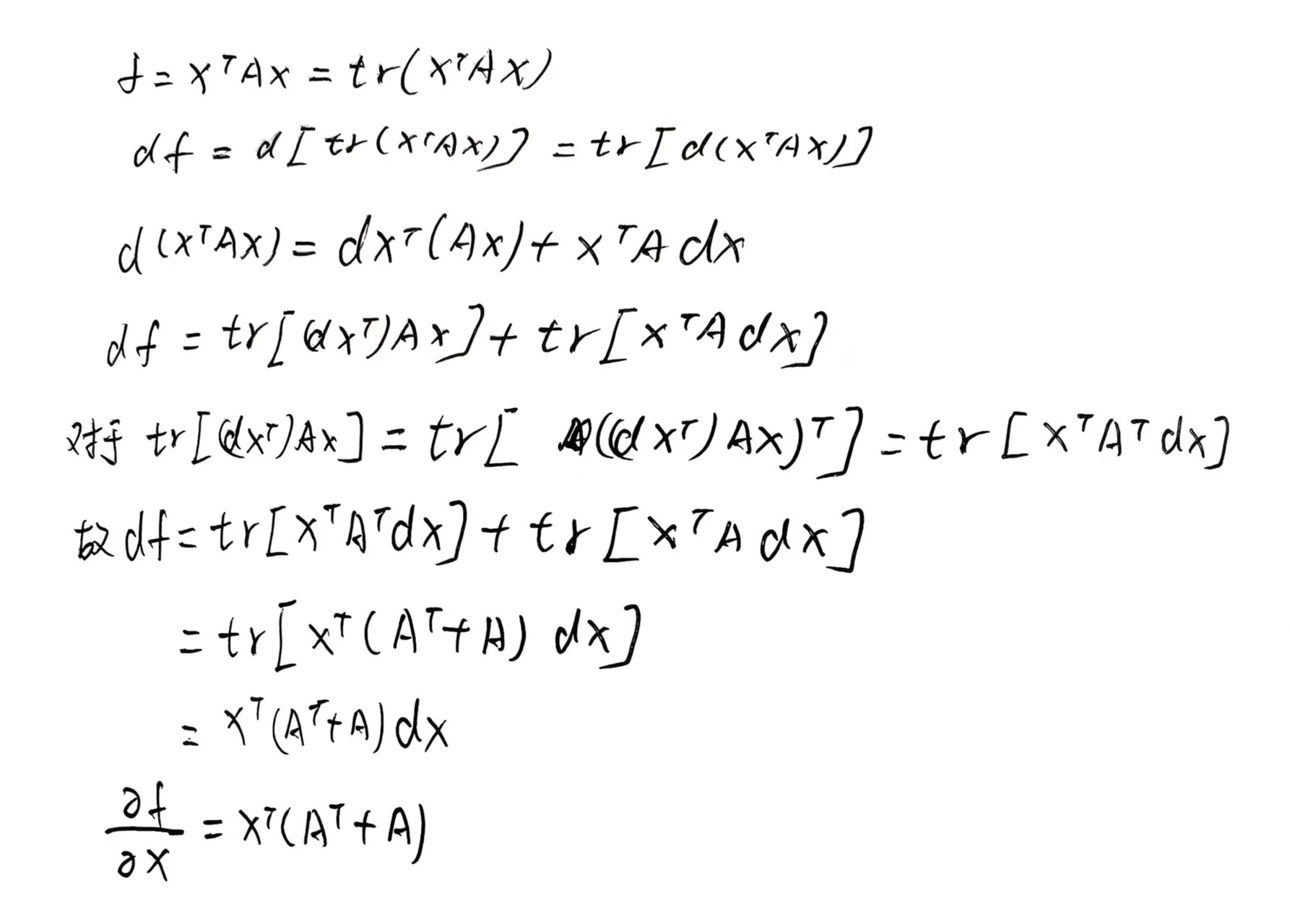
第六章
非线性优化
思路:
问题提出(带噪声的SLAM状态估计)→ 概率框架(最大后验/最大似然估计)→ 数学转化(最小二乘问题)→ 求解方法(非线性优化)→ 具体算法(高斯牛顿/LM法)→ 实践工具(Ceres/g2o)
经过一通操作,成功从问题分析,提出概率问题,得到最大似然估计,再通过高斯分布,取负对数等操作得到一个最小二乘问题:$$min J(x,y)=\sum_{k}e^{T}_{u,k} R^{-1}_{k} e_{{u,k}}+\sum_{k} \sum_{j}e^{T}_{{z,k,j}}Q^{-1}_{{k,j}}e_{{z,k,j}}$$
然后开始解决这个最小二乘问题,方法就是这些非线性优化的办法:牛顿法,高斯牛顿法,列文伯格-马夸尔特方法,最后从代码层面,介绍常用的Ceres和g2o库
由于内容又臭又长,这里只给结论
非线性优化方法
牛顿法
$$H \Delta x=-J$$高斯牛顿法
对$f(x)$进行一阶泰勒展开:$$f(x+\Delta x) \approx f(x)+J^{T}(x)\Delta x$$
推导得到:
把$J(x)J^{T}(x)$记作$H(x)$,把$-J(x)f(x)$记作$g(x)$
得到:$$H\Delta x=g$$
列文伯格-马夸尔特方法
在高斯牛顿法的基础上,给$\Delta x$添加了一个范围,称为信赖区域(Trust Region)。
它定义了在什么情况下二阶近似是有效的,这类方法也称为信赖区域方法(Trust Region Method),在信赖区域里,我们认为近似是有效的,出了这个区域,近似可能会出现问题。
定义一个指标$\rho$来刻画近似的好坏程度:$$\rho=\frac{f(x+\Delta x)-f(x)}{J(x)^{T} \Delta x}$$
分子是实际函数下降的值,分母是近似模型下降的值。
如果$\rho$接近于1,则近似是好的,如果$\rho$太小,说明实际减少的值远小于近似减小的值,则认为近似比较差,需要缩小近似范围;反之,如果$\rho$比较大,则说明实际下降的比预计的更大,我们可以放大近似范围
根据式(6.35),解这个方程来获得梯度,结果是:$$(H+\lambda D^{T}D)\Delta x_{k}=g$$
简化形式是令$D=I$:$$(H+\lambda I)\Delta x_{k}=g$$
(当问题性质较好时,用高斯牛顿,如果问题接近病态,则用LM法)
Ceres与g2o
Ceres与g2o是两种优化库,具体直接看书,看代码即可
例题
书上有一个手写高斯牛顿法的例题,这里写一遍,并把实现代码手敲到这里。
例子是曲线拟合:
考虑一条曲线,方程如下:$$y=\exp(ax^{2}+bx+c)+w$$
定义误差为:$$e_{i}=y_{i}-\exp(ax^{2}_{i}+bx_{i}+c)$$
又知道$J$是误差项的一阶导数,故:
- $\frac{\partial e_{i}}{\partial a}=-x_{i}^{2}\exp(ax_{i}^{2}+bx_{i}+c)$
- $\frac{\partial e_{i}}{\partial b}=-x_{i}\exp(ax_{i}^{2}+bx_{i}+c)$
- $\frac{\partial e_{i}}{\partial c}=-\exp(ax_{i}^{2}+bx_{i}+c)$
故:$$J=\left[\frac{\partial e_{i}}{\partial a},\frac{\partial e_{i}}{\partial b},\frac{\partial e_{i}}{\partial c}\right]^{T}$$
刚才推导的结果是:$$J(x)J^{T}(x) \Delta x=-J(x)f(x)$$
误差所占的权重不同,向里面加入权重:$$J(x) \Sigma^{-1} J^{T}(x) \Delta x=-J(x) \Sigma^{-1} f(x)$$
这个问题中,各个误差间是独立的,权重就可以写为:$$\Sigma^{-1}=diag\left( \frac{1}{\sigma_{1}^{2}}, \frac{1}{\sigma_{2}^{2}}, \dots, \frac{1}{\sigma_{N}^{2}} \right)$$
假设有100个观测数据,即$N=100$,把上述条件带入增量方程,得到:$$\left( \sum^{100}_{i=1} J (\sigma^{2}_{i})^{-1} J^{T} \right) \Delta x_{k}= \sum^{100}_{i=1} - J(\sigma_{i}^{2})^{-1} e_{i}$$
下面使用代码演示:
1 |
|